Assimilation of Machine Learning and Cloud Computing
Abstract
During the era of IoT and Big Data as an emerging technology, it has major impact on all the business sectors. This technology results in generating massive amount of electronic data which contains valuable information. To extract and analyse this information at greater scale the only choice is Cloud computing and Machine Learning technology. The goal is to identify best process for Fraud Prediction and Sales prediction. Ten Machine Learning models are implemented for solving this business question. RandomizedSearchCV is implemented for hyper parameter tuning and time required by model for training and prediction is also evaluated. Even SMOTE is applied for imbalanced dataset. Classification models are validated based on Recall, F1, Confusion Matric ROC-AUC values. Regression Models are evaluated based on MAE and MSE score. Research is conducted using Amazon Web Services and python for predictive analytics by assimilating Machine Learning and Cloud Computing technologies.
Objective
- Perform EDA (Exploratory Data Analysis) for generating preliminary insights from the
dataset.
- Setting up the hyper-parameters for essential Machine Learning model using
RandomizedSearchCV.
- Feature engineering to obtain the impact of important features in the dataset.
- Evaluate and validate results of ML models using metrics like Accuracy, F1, Recall Score
and RMSE, MAE.
- Setting up the services of AWS which will make the implementation of predictive
analysis easier and efficient.
- Setting up AWS S3 permission,SageMaker,EC2 instance and installation of essential packages for performing
cloud integration task.
Methodology
1. Data Collection
2. Data Wrangaling
3. Handeling Imbalanced Data - SMOTE (Synthetic Minority
Oversampling Technique)
4. Setting up AWS: S3,EC2,SageMaker,Jupyter Notebook Configuration
5. Evaluation Metrics (Confusion Matrix, Mean Squared Error)
6. ML Algorithms: Decision Tree, Light GBM, LDA, Random Forest, Ridge, LASSO, Linear Reg., XGBoost, AdaBoost
Analysis & Findings
• Before applying SMOTE there were 123540 class with the
genuine transaction and 2823 with the fraudulent transaction which was later balanced
equally for value of 123540 observation for each class.
• Random Forest is the model which has the best Accuracy, Recall
and F1 score for tuned and default parameters. It consumes 0.296 s for prediction when
parameters are tuned and 0.406 s when parameters are set for default making the most timeconsuming model for prediction.
• In Sales prediction Linear regression is the model with least error rate based on RMSE and
MAE values followed by Ridge Regression. The worst score is for both the tree-based
regressor model where GBT model has MAE=1.8 highest among all the models and XGBoost
having RMSE=4.7 making it the least preferable model for the sales prediction task.
• Total loss of revenue is -3883547.345768667. It also indicated that this loss was due to the large
frequency of fraudulent transaction.
Result
| Model | Accuracy(%) | recall(%) | F1(%) | ROC_AUC(%) | Training Time(s) | Tuning time(s) |
|---|---|---|---|---|---|---|
| Decision Tree | 88.8396484 | 16.20481080 | 27.5994250 | 90.8604781 | 0.308 | 17.4 |
| Random Forest | 98.3325947 | 65.96958174 | 60.5848974 | 77.6681912 | 65.774 | 1302 |
| LDA | 84.4338577 | 12.81414830 | 22.7172717 | 92.0346958 | 0.615 | 5.4 |
| Light GBM | 91.8771696 | 20.51138484 | 33.3181749 | 90.3260558 | 1.448 | 99.5 |
| AdaBoost | 93.2306669 | 21.90321833 | 34.0410219 | 84.9888818 | 180.171 | 2352 |
| Model | Mean Absolute Error | Root Mean Squared Error | Traing time(s) |
|---|---|---|---|
| LASSO | 0.08339548200648535 | 0.11536865510851727 | 0.04 |
| Ridge | 0.0010036470043190342 | 0.001882263872915812 | 0.032 |
| XGBoost | 1.1313262058563323 | 4.793739223668036 | 19.919 |
| Linear Regression | 0.0005448947680783427 | 0.0014938985645114012 | 0.08 |
| Gradient Boosted Tree | 1.8431233686568962 | 3.392379767811959 | 39.152 |
View Presentation Source Code Link to Project Report
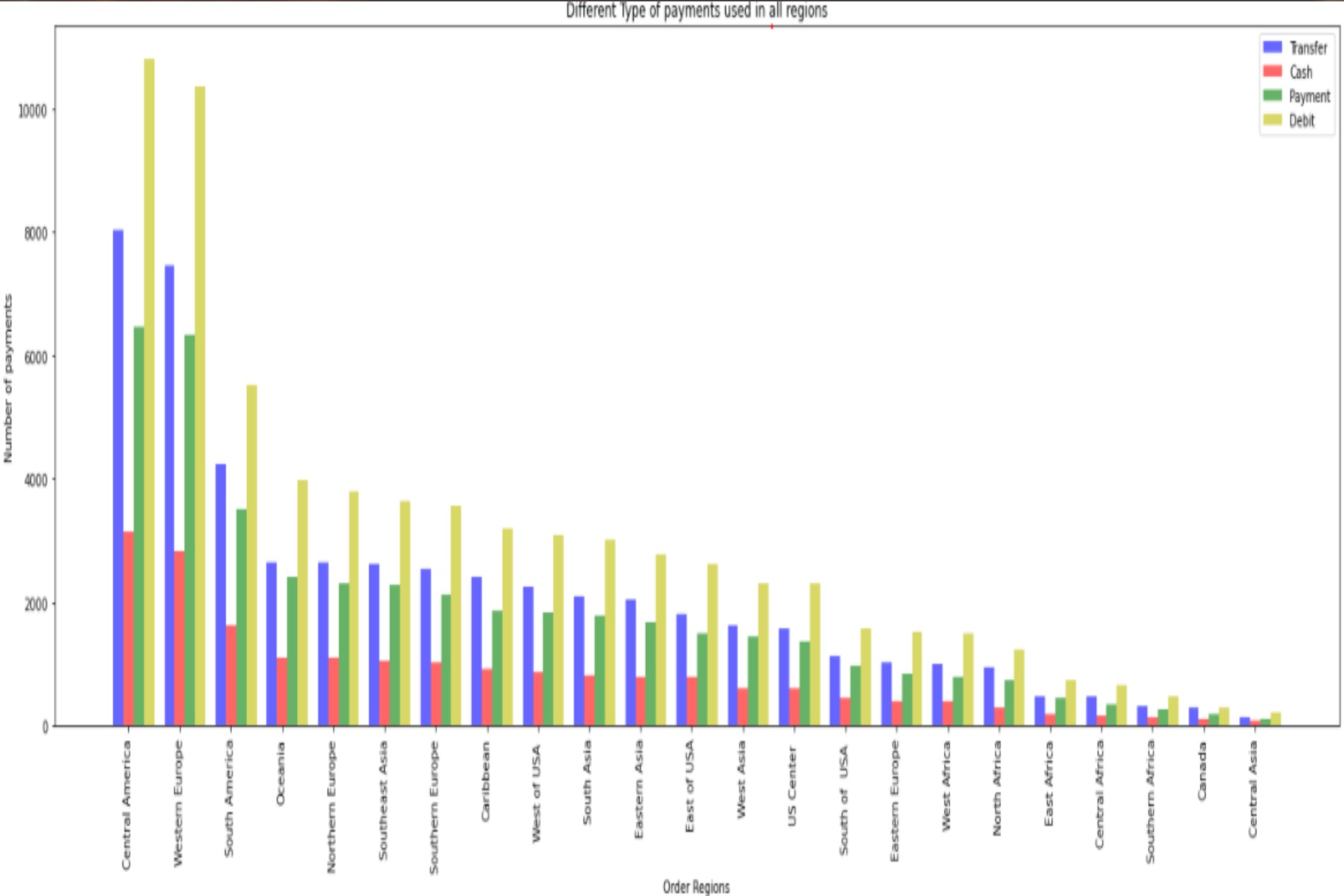
Payment Type v/s Region
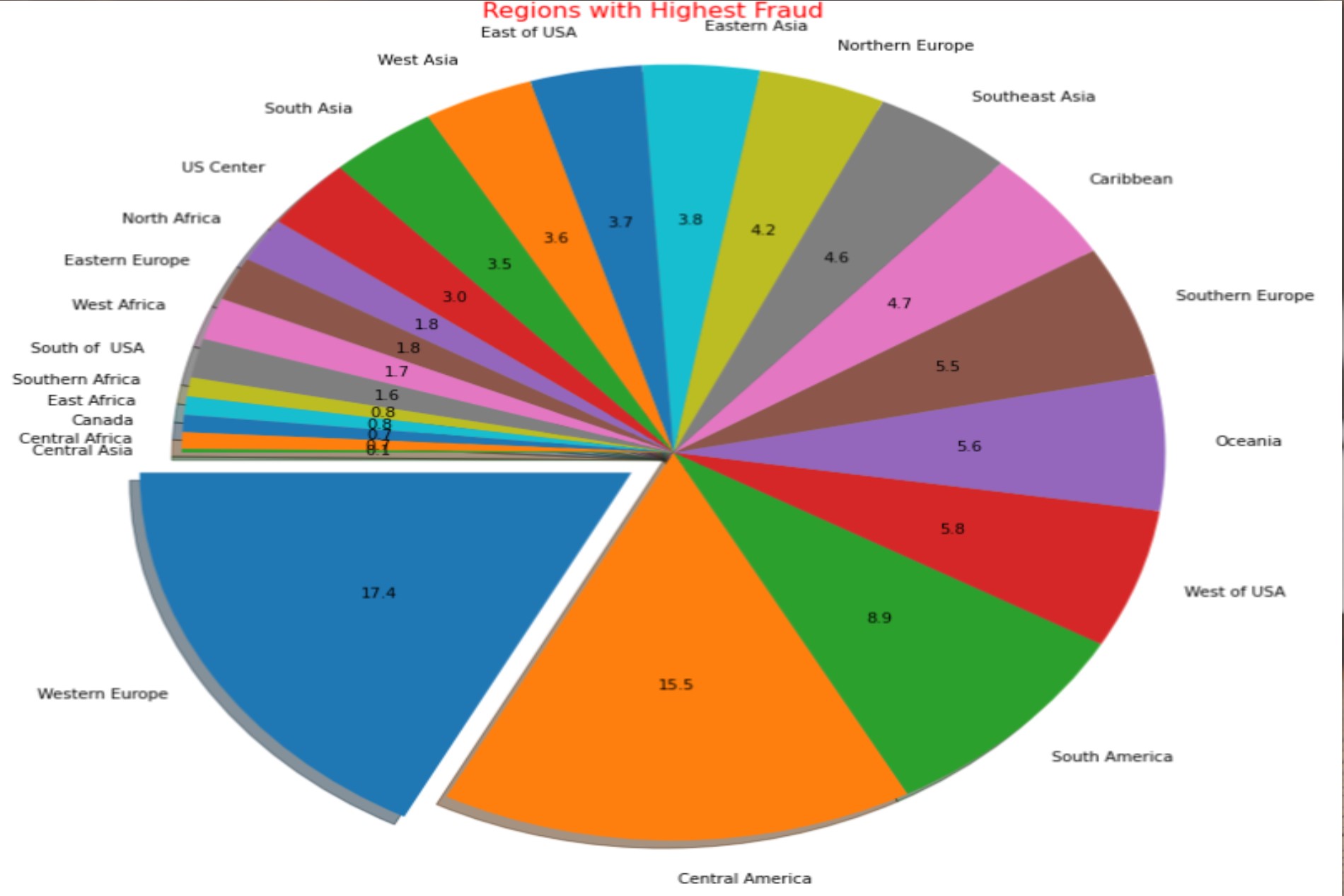
Highest Fraud Region
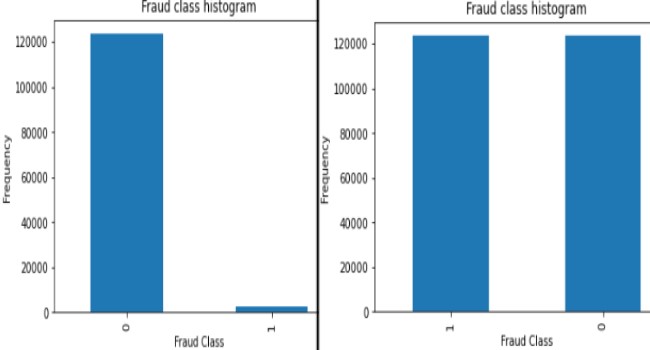
Balanced Data-SMOTE
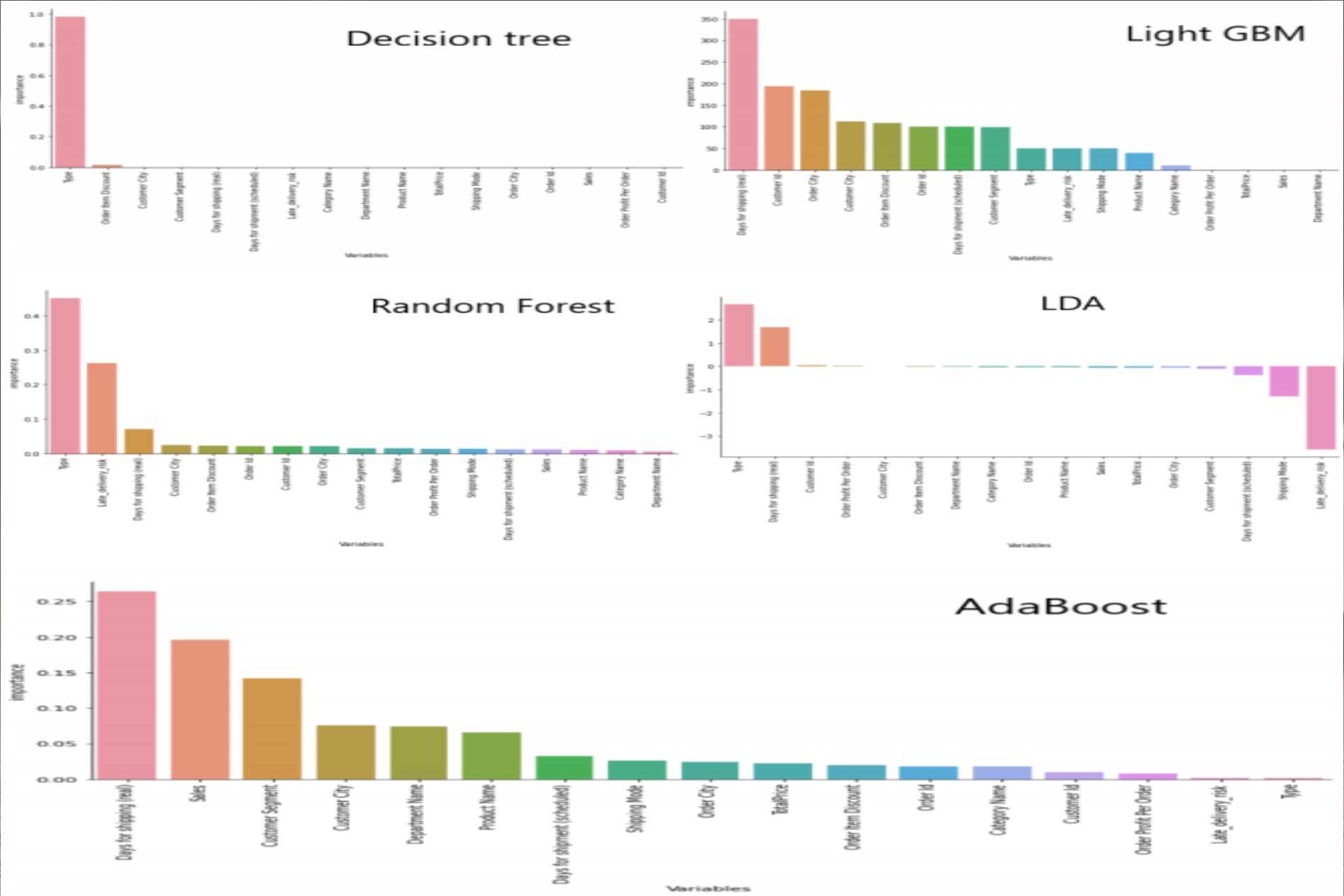
Significant Features
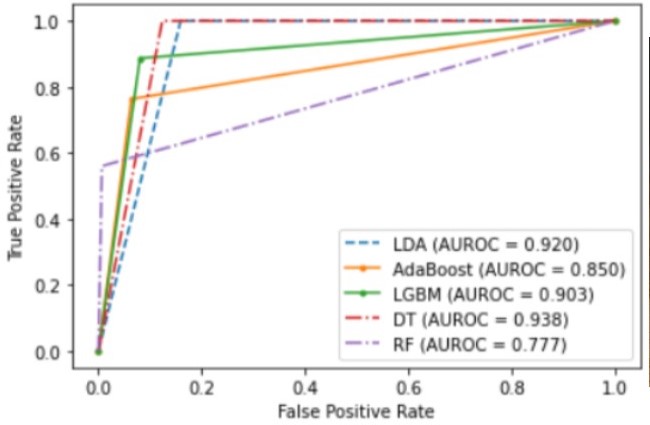
ROC Plot
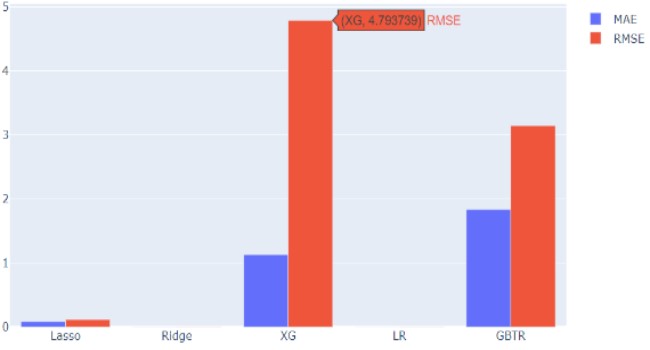
MAE-RMSE Plot